

















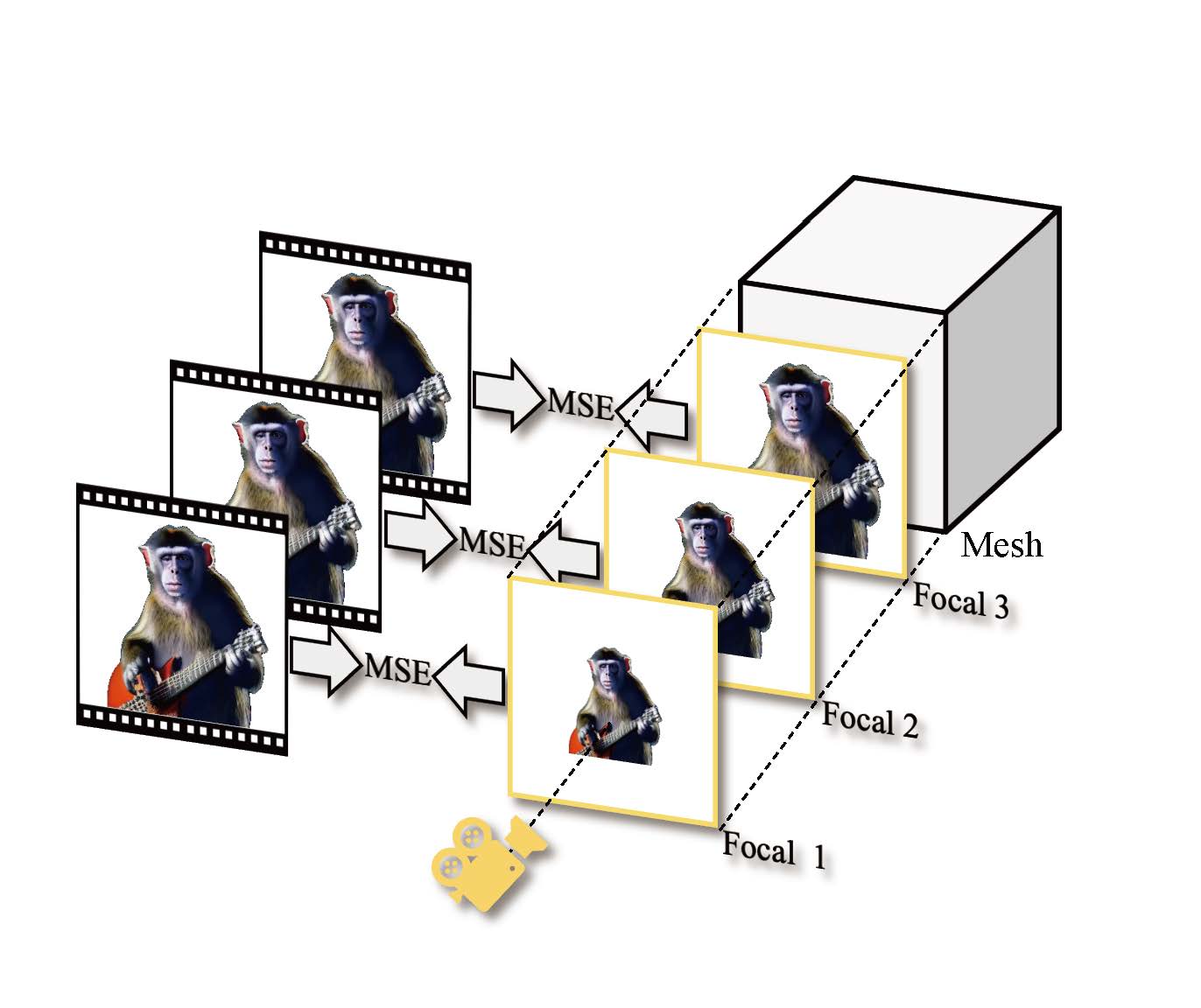
(a) Focal Alignment
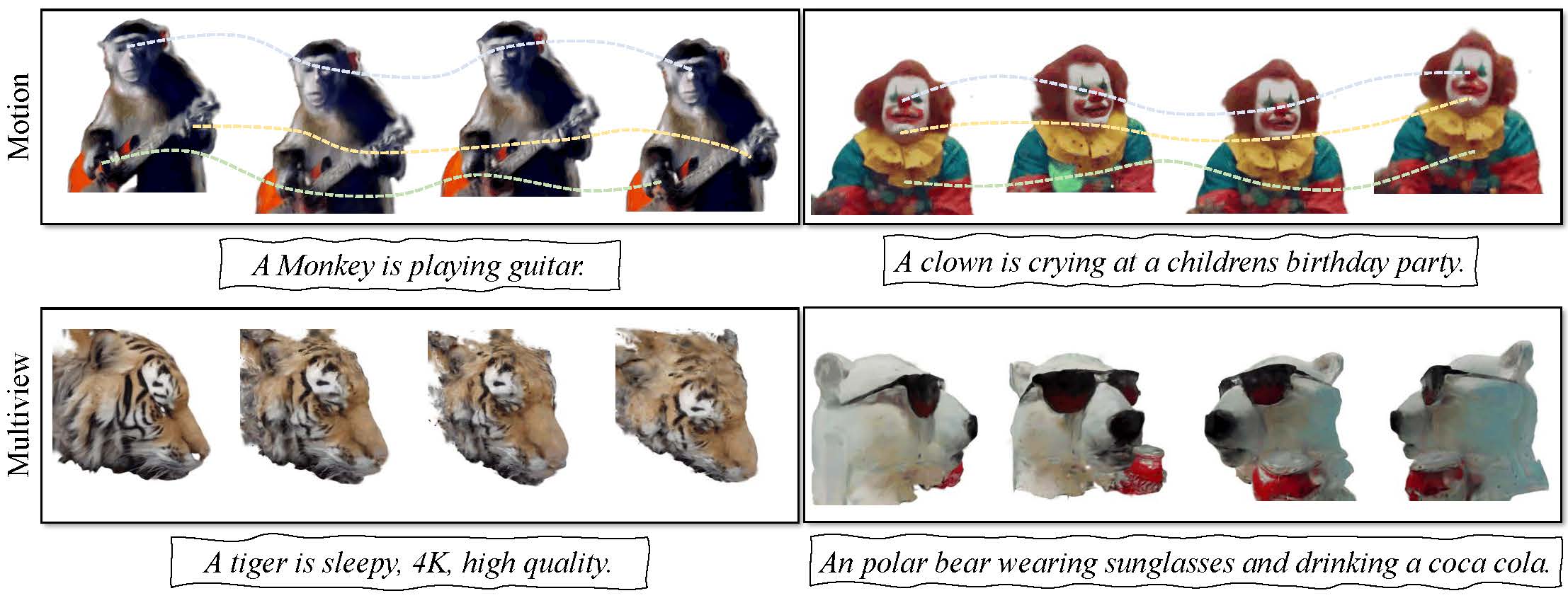
Figure 1: Text-to-4D synthesis results of our PLA4D. Top: we show the motion sequences of the 4D targets. Dotted lines represent the motion trajectories controlled by the deformation network at different timesteps. Bottom: we present the multiple views of 4D objects at one timestep.
As text-conditioned diffusion models (DMs) achieve breakthroughs in image, video, and 3D generation, the research community’s focus has shifted to the more challenging task of text-to-4D synthesis, which introduces a temporal dimension to generate dynamic 3D objects. In this context, we identify Score Distillation Sampling (SDS), a widely used technique for text-to-3D synthesis, as a significant hindrance to textto-4D performance due to its Janus-faced and texture-unrealistic problems coupled with high computational costs.
In this paper, we propose Pixel-Level Alignments for Text-to-4D Gaussian Splatting (PLA4D), a novel method that utilizes text-tovideo frames as explicit pixel alignment targets to generate static 3D objects and inject motion into them. Specifically, we introduce Focal Alignment to calibrate camera poses for rendering and GS-Mesh Contrastive Learning to distill geometry priors from rendered image contrasts at the pixel level. Additionally, we develop Motion Alignment using a deformation network to drive changes in Gaussians and implement Reference Refinement for smooth 4D object surfaces. These techniques enable 4D Gaussian Splatting to align geometry, texture, and motion with generated videos at the pixel level.
Compared to previous methods, PLA4D produces synthesized outputs with better texture details in less time and effectively mitigates the Janus-faced problem. PLA4D is fully implemented using open-source models, offering an accessible, user-friendly, and promising direction for 4D digital content creation.
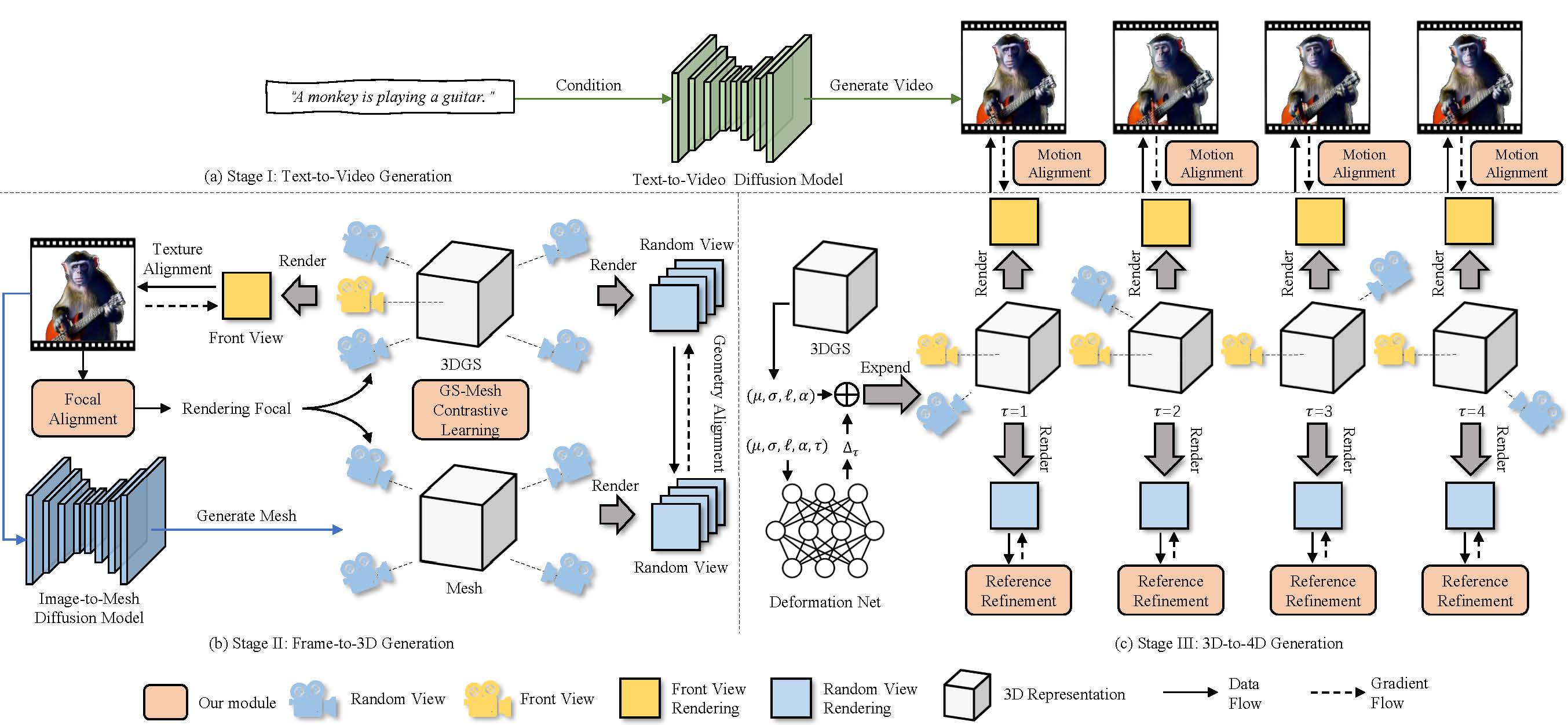
Figure 2: Pipeline of PLA4D. (I) Text-to-Video generation: generating video as the pixel-level alignment targets for 3D and 4D content. (II) Frame-to-3D generation: applying GS-Mesh contrastive learning and focal alignment for texture and geometry alignment, which constructs static 3D Gaussians with correct geometry and detailed texture based on the first frame. (III) 3D-to-4D generation: PLA4D employs motion alignment and reference refinement methods to inject motion into 3D Gaussians.
(a) Focal Alignment
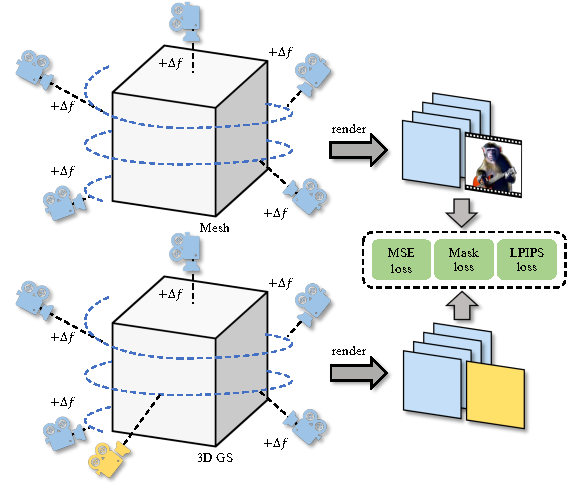
(b) GS-Mesh Contrastive Learning.
Figure 3: Focal alignment and GS-Mesh contrastive learning in frame-to-3D stage. (a) We render multiple front-view images and calculate the MSE with the first frame for searching the matched focal. (b) We collect two sets of images: one of 3D Gaussians and another of mesh renderings, both captured using the same random camera poses. We include the first generated frame and the front-view rendering in these two sets. Then, we calculate the MSE loss, Mask loss, and LPIPS loss between the corresponding images from these sets.

Figure 4: PLA4D generates more realistic targets than MAV3D and AYG by pixel-level alignments. Leveraging the focal alignment method and GS-Mesh contrastive learning, PLA4D effectively avoids multi-head issues (see Subfig.(b)) and potential geometric defects(see Subfig.(a) and Subfig.(c)), thus maintaining excellent geometric configurations. After injecting motion, our proposed motion alignment method effectively prevents short-term motion flicker (see Subfig.(d)), while the reference refinement method prevents surface fracture caused by Gaussian points’ displacement.

Figure 5: Ablation studies. If no focal alignment or GS-Mesh contrastive learning, the 4D object loses its detailed texture and correct geometry. Without motion alignment, a 4D object degenerates into a static object. Absent reference refinement, the displacement of Gaussians causes surface tearing.
In this paper, we introduce PLA4D, a framework that leverages text-driven generated video as explicit pixel alignment targets for 4D synthesis. Our approach incorporates GS-Mesh contrastive learning and focal alignment, which ensures geometry consistency from the mesh and produces textures as detailed as those in the generated video frames. Additionally, we have developed a novel motion alignment method and reference refinement technology to optimize dynamic surfaces. Compared to existing methods, PLA4D effectively avoids multi-head issues and generates 4D targets with rich textures, accurate geometry, and smooth motion in significantly less time. Furthermore, PLA4D is constructed entirely using existing open-source models, eliminating the need for pre-training any diffusion models. This flexible architecture allows the community to freely replace or upgrade components to achieve state-of-the-art performance. We aim for PLA4D to become an accessible, user-friendly, and promising tool for 4D digital content creation.
@misc{miao2024pla4d,
title={PLA4D: Pixel-Level Alignments for Text-to-4D Gaussian Splatting},
author={Qiaowei Miao and Yawei Luo and Yi Yang},
year={2024},
eprint={2405.19957},
archivePrefix={arXiv},
primaryClass={cs.CV}
}